(Automated) business processes evolve over time! And they usually evolve faster than IT systems do.
So how can business process changes be delivered to the users quickly?
Let’s look at an example:
Assume we have a process for vacation planning for the staff of a large company. Initially the process was automated based on the knowledge of the human resource department. After 2 months new insights require a process change. The process should be optimized to speed up the decison whether vacation is granted or not. The process has evolved and the changes have to be put in place as soon as possible. This is a common situation and actually one of the promises of business process management is: Deliver business value fast.
Sounds simple, but how can we deliver the changed process?
There are serveral options to put the changed process in place:
Option 1: Parallel
The changed process coexists with the initial one for a period of time. Existing process instances must continue with the inital process definition.
Example: Users of the process are gradually trained to use the changed process. Some departments can still use the initial process, some use the new one. The process is triggered by IT systems as well. Those systems should have a smooth upgrade path.
Action: Create a new version of the process and deploy it in parallel to the one already in place.
|--- Startable V1 -------->
|--- Instances V1 -------->
|--- Startable V2 --------->
|--- Instances V2 -------->
Option 2: Merge
The changed process replaces the initial one. Existing process instances must continue using the changed process definition.
Example: Law changes render invalid the initial process. As of now all processes, including already running instances, must run with the latest process definition.
Action: Create a new version of the process and migrate existing instances to the new process definition.
|--- Startable V1 ------|--- Startable V2 --------->
|--- Instances V1 ------|--- Instances V1 + V2 ---->
Option 3: Phase Out
The changed process replaces the initial one. Existing process instances must continue with the inital process definition.
Example: Process analysis caused the process to be optimized, so that it can be executed in less time. All users should immediately use the changed process.
To keep effort low, already running process instances should continue running with the inital process definition.
Action: Create a new version of the process and deploy it in addition to the one already in place. Prevent the initial process version to be started by disabling the start events.
|--- Startable V1 --------|
|--- Instances V1 --------------------|
|--- Startable V2 --------->
|--- Instances V2 -------->
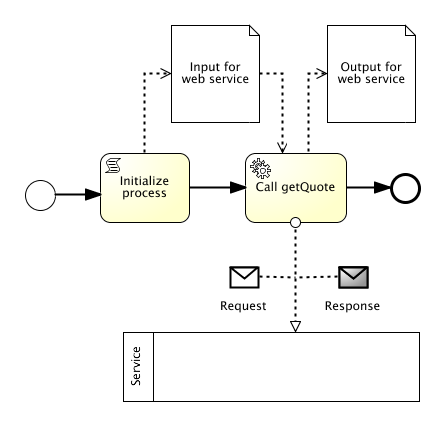
Be aware of endpoints:
If process versions are provided in parallel like in scenario 1 and 3 and connected to technical endpoints, for instance filedrops or web services, those endpoints might collide. Changing the structure of an endpoint, for instance the message payload, might cause incompatibility as well. In those cases (which are likely to happen) the endpoints must be versioned. Alternatively a dispatching mechanism can be used to route messages to the appropriate process version.
As you can see versioning is am important concept for process evolution. Which strategy to use depends on the process and the particular business requirements. The options introduced in this blog post might help to take the right decision. Make sure your process platform supports the options you need.