The slide deck from my JAX 2017 sessions can be downloaded here.
Agile – Mythen, Trends, Best Practices
Mit Prozessen, Services und Regeln zur effizienten Kreditvergabe
The slide deck from my JAX 2017 sessions can be downloaded here.
Agile – Mythen, Trends, Best Practices
Mit Prozessen, Services und Regeln zur effizienten Kreditvergabe
In 2016 PLEUS Consulting supported Bank11 in the development of their brand new sales financing system VICTOR 3.0.

|
Bank11 is a credit institution that specializes in sales financing. In 2016 the bank decided to replace their existing software with something new. To be able to meet the challenging requirements in terms of quality, customer satisfaction and process efficiency they decided to build their own solution.
The front-ends were developed using modern web technologies such as Javascript, HTML5, CSS and Angular. For the backend Java Enterprise (JEE) and a Sustainable Service Design approach was utilized to design and build a backend with a high degree of reuse and scalability. The service landscape was established using Domain Driven Design principles. On the technical side, PLEUS Consulting supported the teams as Master Developer and Architecture Owner. In the area of agile techniques, PLEUS Consulting supported the development teams as Scrum Master and Agile Coach. Although not 100% tension free, the combination of those roles worked quite well. With these roles the bank received thorough support in the areas of technology and methodology. From the beginning we tried to align technology and business as much as possible, creating a people centered architecture. Central to the strategy were BPMN process models, graphical business rules and visual service contracts. In order to create appealing front-ends for the car dealers and the back office of the bank we worked closely with user interface specialists which were members of the cross functional teams. Web stack technologies allowed us to create individual and great looking front-ends. Agile frameworks such as Scrum organized the development teams and created valuable software together with the customer within a short period of time. The project has shown that with a combination of modern technologies and agile approaches a very short concept to market cycle can be achieved, creating competitive advantages. It also demonstrates that it is possible to establish an agile culture in rather traditional business domains. |
You can read more details about the project in the official success story. If you want to find out more come to watch my talks at JAX 2017 in Mainz.

Between the 8th and 12th May 2017 JAX will be taking place at Rheingold Halle in Mainz.
On the 8th I am going to give a presentation about Agile trends, myths and best practices. . In this talk I will show why Agile is the way to go and what it actually means to work with Agile rather than just applying Scrum or Kanban rules.
On the 9th I will share insights from a banking projekt in 2016. This technical talk will show how to combine current architectural patterns such as sustainable service orientation, process automation and business rules to create an architecture that evolves around people.
You can see the timeslots on the JAX website. I look forward to seeing you there.
In part one I’ve shown how to turn contracts into code. In this part I am going to show how to turn contracts into documentation.
Using the contract as a model for both code generation and documentation can save a lot of time. That is because the contract represents a single source of truth, which can be used by developers and business people alike. Just like you would probably do when you design BPMN models together with people from business you can design service contracts in the same way. Designing service contracts together with business people fosters the notion of services as business assets rather than just technical artefacts. Beside the time savings this creates mutual understanding amongst developers and business people. It facilitates collaboration and aligns business and IT. It work especially well in agile contexts in which business and IT work closely together.
But in order to be able to generate proper documentation from XML schema it is necessary to document the schema very thoroughly. Luckily there is a standardized way to do that using <xs:annotation> and <xs:documentation>. The following listing shows how to do it right.
<xs:element name="PerformSimpleCalculationRequest">
<xs:annotation><xs:documentation>Performs a simple calculation</xs:documentation></xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element name="operation" type="tns:Operation" minOccurs="1" maxOccurs="1">
<xs:annotation>
<xs:documentation xml:lang="EN">Operation to perform</xs:documentation>
<xs:documentation xml:lang="DE">Operation zur Ausführung</xs:documentation>
</xs:annotation>
</xs:element>
...
</xs:sequence>
</xs:complexType>
</xs:element>
You can see the full listing in the previous blog post.
It is best practice to document every aspect in the schema in a way that can be understood by humans. Ideally not only by technicans but by business people as well. To achive that it is essential to use the right language from the respective business domain. As shown in the listing it is even possible to add documentation in multiple languages.
As XML schema itself is XML we can easily validate and transform it to HTML using XSD and XSLT. A template can be found as part of the example project.
The stylesheet can be linked to the XSD using the directive <?xml-stylesheet type=”text/xsl” href=”contract.xsl”?> within the XSD. If you open the XSD in a web browser it will be transformed right away and show the HTML output.
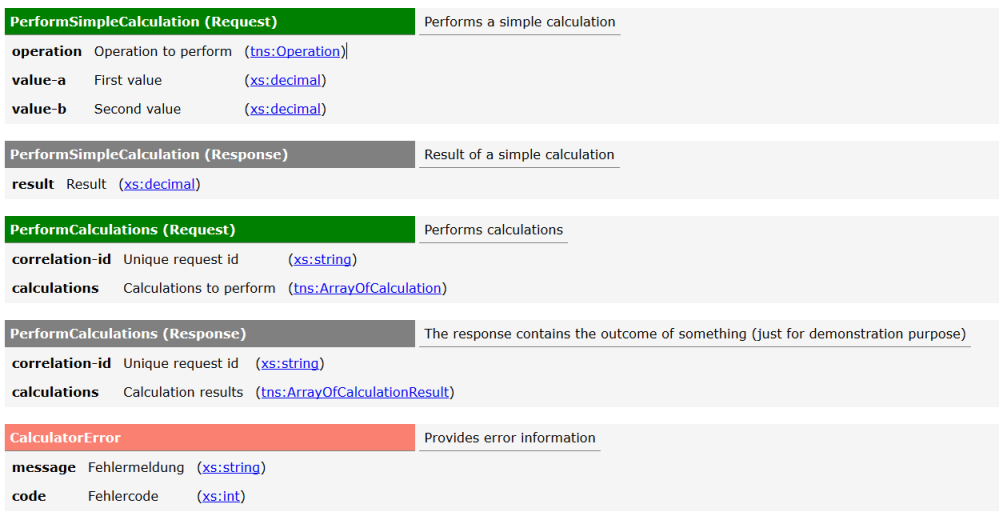
Alternatively you can transform the XSD on the commandline using msxsl.exe. Just type the following to generate the HTML documentation.
msxsl calculator.xsd contract.xsl -o calculator.html
Another option is to automate the transformation process using the Maven plugin org.codehaus.mojo:xml-maven-plugin as you can see in the following excerpt from the POM file.
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>xml-maven-plugin</artifactId>
<version>1.0</version>
<inherited>false</inherited>
<executions>
<execution>
<id>transform</id>
<goals>
<goal>transform</goal>
</goals>
<phase>install</phase>
</execution>
</executions>
<configuration>
<transformationSets>
<transformationSet>
<dir>api/src/main/resources/xsd</dir>
<stylesheet>${project.basedir}/repo/transform/xsl/contract.xsl</stylesheet>
<outputDir>target/repository</outputDir>
<fileMappers>
<fileMapper implementation="org.codehaus.plexus.components.io.filemappers.RegExpFileMapper">
<pattern>^(.*)\.xsd$</pattern>
<replacement>contract.html</replacement>
</fileMapper>
</fileMappers>
</transformationSet>
</transformationSets>
</configuration>
</plugin>
The result is a HTML contract documentation in the target/repository directory. This documentation can for instance be uploaded to a Wiki which serves as a service repository. It is lightweight, easy to use and highly recommended as it greatly helps to increase the likelyness of service reuse.
It is definitely recommended to develop service contracts in workshops with people from IT and business. The person who moderates such a workshop can be called a BizDev, as he/she needs understanding of the business domain and technology alike. Doing that can greatly reduce misconceptions and create awareness of services as reusable business assets. Give it a try!
Since BPMN2.0 it is not only possible to design processes but to also execute them using a process engine. The process flow has a appropriate visual representation in the standard. But executable processes are mostly data driven. They interact with external services and exchange data with them. In addition to that processes maintain their own internal state. So a common requirement is to model the process internal state and connect to external services using the service data representation. BPMN is capable to include data definitions based on WSDL and XML Schemas, although the capabilities of the tools (that I know) to visualize data are somewhat limited.
In this blogpost I would like to show you how data looks like in BPMN and how a process can be linked in a standardized way to existing services based on WSDL and XSD.
The process is as simple as possible. The service is based on a BiPRO service description. The BiPRO is a standardization organisation in the German insurance market that standardizes processes and services at a technical and business level.
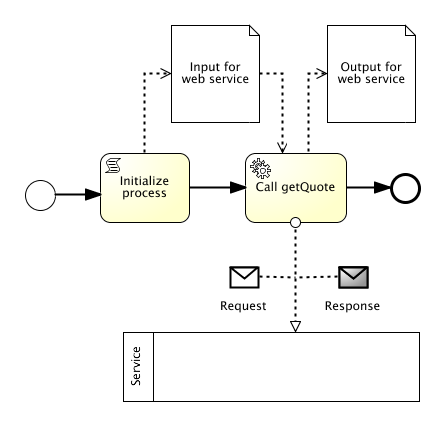
Below you see a simplyfied version in plain BPMN (when you import the bpmn below you will only see the events and tasks).
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="definitions" xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:bpmn="http://schema.omg.org/spec/BPMN/2.0"
xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI"
xmlns:dc="http://www.omg.org/spec/DD/20100524/DC"
xmlns:di="http://www.omg.org/spec/DD/20100524/DI"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.pleus.net/example"
xmlns:tns="http://www.pleus.net/example"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:nachrichten="http://www.bipro.net/namespace/nachrichten"
xmlns:bipro="http://www.bipro.net/namespace"
xsi:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL http://bpmn.sourceforge.net/schemas/BPMN20.xsd">
<!-- WSDL Import -->
<import importType="http://schemas.xmlsoap.org/wsdl/"
location="KompsitService_2.4.3.1.1.wsdl"
namespace="http://www.bipro.net/namespace" />
<!-- Item definition. Link to the external WSDL/XSD structure. structureRef: QName of input element -->
<itemDefinition id="getQuoteRequestItem" structureRef="nachrichten:getQuote" />
<itemDefinition id="getQuoteResponseItem" structureRef="nachrichten:getQuoteResponse" />
<!-- Message definitions. Link to the item definition. Can be visualized by using DI -->
<message id="getQuoteRequestMessage" itemRef="tns:getQuoteRequestItem" />
<message id="getQuoteResponseMessage" itemRef="tns:getQuoteResponseItem" />
<!-- Interface definition. implementationRef = QName of WSDL Port Type -->
<interface name="Komposit Interface" implementationRef="bipro:KompositServicePortType">
<!-- Operation: implementationRef = QName of WSDL Operation -->
<operation id="getQuoteOperation" name="getQuote Operation" implementationRef="bipro:getQuote">
<!-- Links to the message definitions -->
<inMessageRef>tns:getQuoteRequestMessage</inMessageRef>
<outMessageRef>tns:getQuoteResponseMessage</outMessageRef>
</operation>
</interface>
<process id="servicecall">
<!-- Datasources and targets for the service call (process state). Can be visualized by using DI and dataObjectReferences -->
<dataObject id="dataInputOfProcess" name="Input for webservice" itemSubjectRef="xs:string"/>
<dataObject id="dataOutputOfProcess" name="Output for webservice" itemSubjectRef="xs:string"/>
<!-- Process start -->
<startEvent id="start" />
<sequenceFlow id="flow1" sourceRef="start" targetRef="initScript" />
<!-- Initialization of process data -->
<scriptTask id="initScript" scriptFormat="groovy" name="Initialize process">
<script>
def temp = "2.4.3.1.1"
execution.setVariable("dataInputOfProcess", temp)
</script>
</scriptTask>
<sequenceFlow id="flow2" sourceRef="initScript" targetRef="webService" />
<!-- Web Service call -->
<serviceTask id="webService" name="Call getQuote" implementation="##WebService" operationRef="tns:getQuoteOperation">
<!-- Defines the inputs and outputs and links to item definitions -->
<ioSpecification>
<dataInput itemSubjectRef="tns:getQuoteRequestItem" id="dataInputOfServiceTask" />
<dataOutput itemSubjectRef="tns:getQuoteResponseItem" id="dataOutputOfServiceTask" />
<inputSet>
<dataInputRefs>dataInputOfServiceTask</dataInputRefs>
</inputSet>
<outputSet>
<dataOutputRefs>dataOutputOfServiceTask</dataOutputRefs>
</outputSet>
</ioSpecification>
<!-- Defines the mapping between process data and service input -->
<dataInputAssociation>
<sourceRef>dataInputOfProcess</sourceRef>
<targetRef>dataInputOfServiceTask</targetRef>
<assignment>
<from>
bpmn:getDataObject('dataInputOfProcess')
</from>
<to>
bpmn:getDataInput('dataInputOfServiceTask')/BiPROVersion/
</to>
</assignment>
</dataInputAssociation>
<!-- Defines the mapping between process data and service output -->
<dataOutputAssociation>
<sourceRef>dataOutputOfServiceTask</sourceRef>
<targetRef>dataOutputOfProcess</targetRef>
<assignment>
<from>
bpmn:getDataOutput('dataOutputOfServiceTask')/BiPROVersion/
</from>
<to>
bpmn:getDataObject('dataOutputOfProcess')
</to>
</assignment>
</dataOutputAssociation>
</serviceTask>
<sequenceFlow id="flow3" sourceRef="webService" targetRef="end" />
<!-- Process end -->
<endEvent id="end" />
</process>
Now let’s look at the example step-by-step.
1. Import the service: Line 16-18 imports the WSDL file that includes the types and messages used by the external service that we want to call from the process.
2. Define the items: Line 21-22 defines items that act as links to the types defined in the imported WSDL and XSD files.
3. Define the messages: Line 25-26 defines messages to be used in the interface definition that we see in the next step. Messages can be visualized by modeling tools provided that DI Information is present in the model.
4. Define the interface: The interface is the equivalent to the WSDL port type in BPMN. It is defined in line 29-36. So far we have itemDefinitions that link to the XSD-messages and an interface that links to the WSDL-port type. The inMessageRef and outMessageRef elements use the messages defined in step 3 to indirectly reference the itemDefinitions.
5. Define the process variables: The process maintains state. This state is defined in the form of dataObjects in line 41-42. Please note that the links to the external service are defined outside the process (which begins in line 38). The dataObjects are defined inside the process as they represent the data that is maintained by the respective process instances. By the way, when importing the process in a modeling tool, dataObjects are not visualized. To visualize dataObjects as a paper sheet, dataObjectReferences can be used. In this simple example we just use a string as input and output which transports a version information send to the BiPRO service and back. In a more complex senario this could be a type from an imported XSD.
6. Initialize the process: A simple BPMN script task (line 50-55) is used to initialize the dataObject dataInputOfProcess. It just sets the version to 2.4.3.1.1.
7. Link the serviceTask: The most complex part is the serviceTask (line 60-102). The operationRef attribute (line 60) links to the operation which is part of the interface definition (line 31). This is the web service operation to be called when the serviceTask is executed. The serviceTask comprises the elements ioSpecification (line 63-72), dataInputAssociation(line 75-86) and dataOutputAssociation (line 89-100). ioSpecification can be seen as a logical port that describes the service input and output from the perspective of the service. The itemSubjectRef attribute on the dataInput and dataOutput elements (line 64-65) link to the itemDefinitions (line 21-22) and as such to the data structures in the WSDL files. The id together with the inputSet and outputSet (line 66-71) define the connection points the serviceTask offers for sending and receiving data. dataInputAssociation and dataOutputAssociation map the dataObjects (process data) to the connection points or in other words to the request and response structures of the service (service data).
When the serviceTask webService is called, the process data from the dataObject dataInputOfProcess is copied to the web service request message nachrichten:getQuote/BIPROVersion. Then the service is called. After the service call finished, the version is copied from the response message nachrichten:getQuoteResponse/BIPROVersion to the dataObject dataOutputOfProcess.
This blogpost has shown how to link WSDL/XSD based services to BPMN processes in a standardized way.
Even if automated process execution is not in focus, it can be important to unambiguously link services to processes to create an integrated view of the entire process including its data.
In this tutorial I would like to show how to visualize BPMN files in a web browser.
All we need is jQuery for easy DOM navigation, XMLJS to parse the BPMN file and Raphael to visualize it. Since BPMN version 2.0 the BPMN XML file contains additional diagram interchange information. This information together with the actual process data can be used to draw process diagrams from the XML with little effort.
Step 1: Create the process
First we create a simple BPMN2.0 process like the one below using our tool of choice. In this case it was created with Signavio Modeler.

If we open the bpmn file in a text editor it looks like this:

What we see is that in addition to the actual process information it contains elements named BPMNShape and BPMNEdge. BPMNShape contains the bounds of the shape whereas BPMNEdge contains the path of the respective shape connector. This is the diagram interchange format which specifies the size and location of the graphical elements and paths.
Step 2: Prepare the HTML page
We need a simple HTML page that loads the required scripts for jQuery, XMLJS, Raphael and of course our own script bpmnjs.js.

The textarea element (line 20) contains the BPMN data. It is omitted here for the sake of readability.
The div element (line 23) specifies the drawing area that is needed to output the graphics.
Both are needed to initialize BPMNJS in the document ready event (line 14-15).
Step 3: Parse the DI elements using XMLJS
The following listing shows the parsing loop for the BPMN shapes within the plot function of BPMNJS.

First the XMLJS dom parser is initialized (line 49-51). The bpmndi namespace is determined in the getNamespaces function at line 54. Line 57 obtains all shapes. The rest of the listing iterates over the shapes, gets positions, sizes and bpmnElement-ids of the related BPMN elements and passes them to the paintShape function which performs the painting. The parsing loop for the edges is almost identical. The simplest possible paintShape implementation would look like the following.

The constructor function (lines 2-4) connects Raphael with our div and stores the Raphael instance in a variable called paper. The paper is used in the function paintShape which draws a simple rectangle using the given coordinates (line 8).
The result looks like this:

A few lines of JavaScript and we see the BPMN skeleton already. Not too bad.
Step 4: Find related process elements
In order to draw specific BPMN elements we have to determine the element type. The bpmnElement attribute that we have got in step 3 helps us to do that. We use it to get the process element by issuing an xPath expression on the DOM as you can see in the next listing (line 128).

The localName of the element is the name of the BPMN element an therefore the type such as startEvent. With this information we can implement a dispatcher to draw all BPMN elements individually (lines 130-133).
Step 5: Draw elements using Raphael and CSS
Raphael is a powerful JavaScript library that allows to paint graphical primitives easily.
The next listing shows an implementation to draw a basic BPMN task.

First the rectangle is painted (line 3) then the text is written onto the shape (lines 6-8). We can even apply CSS stylesheets to the shapes that allow very flexible customization without changing the JavaScript code (line 10). The function getCss determines the CSS class name. The simplest implementation just uses the elementType as CSS class name as you can see in the following CSS snippet.

After implementing some more type specific paint functions the result looks like this:

Step 6: Highlight paths
One of the advantages of painting the BPMN model at runtime over a static JPG like the one shown in step 1 is that it allows interactivity. For instance we could highlight the actual token flow in the model. To do that we need information about the executed BPMN steps. This can typically be obtained from a process tracking system which is part of almost every BPM product. To achieve highlighting we extend the getCss function to return a different class if the current shape is in the list of already executed steps.

We add the postfix -high to the CSS class in case the element should be highlighted. By specifying for example the class .task-high we can achieve highlighting for shapes and edges. The result is show below.

Step 7: Add interactivity
Finally we can even add interactivity to the model with a little help from Raphael.

As this can not be demonstrated using static images you can find an interactive version here. In this version you can hover over and click individual shapes to make them react.
Summary
With the help of jQuery, XMLJS, Raphael and less than 300 lines of JavaScript code, this blog post has shown how to create interactive BPMN models in your web browser. The complete demo can be downloaded here.
If you ever tried to create an execution environment to automate business- or integration processes based on Open Source products, you know that this is not an easy task. Although Open Source products like Activiti or Apache Camel are of high quality, they do not run with production grade quality out-of-the-box. For serious usage scenarios typically a lot of work is required to integrate those products into a sound platform. This fact hinders companies to use those great products and turn to closed source alternatives from Oracle, Appian or Inubit, just to name a few.
Now there is an interesting alternative called oparo. oparo is an integrated process automation platform based on rock solid Open Source products. oparo is not limited to BPMN processes only. It rather focuses on the entire process spanning business, workflow, mediation and integration.
The platform does all the plumbing required to turn single products such as Activiti, Apache Camel, Apache ActiveMQ, Lucene/Solr, etc. into a platform that can be used out-of-the box. Even better, oparo is entirely ASF2.0 licensed (today and tomorrow) which offers broad usage options and does not involve any hidden costs for enterprise features.
oparo shields the process engineer (the guy who analyses and automates processes) as much as possible from low level technical tasks such as connecting and transforming Camel and Activiti message payloads. It offers a unified development approach for the process engineer to focus on business functionality instead of technical plumbing. Moreover it comprises additional valuable services such as process flow tracking, humantask integration or a registry. Due to oparos service binding approach, those services can be easily integrated in existing IT landscapes using almost any technology (e.g. .NET, JEE, HTML5/JS/CSS). The runtime is scalable (in terms of technology and licenses), the set up is automated and the whole platform is based on proven standards.
If that sounds promising, you can give it a try. You can find more information and a downloadable jumpstart distribution at oparo – the efficient process platform (German only)
(Automated) business processes evolve over time! And they usually evolve faster than IT systems do.
So how can business process changes be delivered to the users quickly?
Let’s look at an example:
Assume we have a process for vacation planning for the staff of a large company. Initially the process was automated based on the knowledge of the human resource department. After 2 months new insights require a process change. The process should be optimized to speed up the decison whether vacation is granted or not. The process has evolved and the changes have to be put in place as soon as possible. This is a common situation and actually one of the promises of business process management is: Deliver business value fast.
Sounds simple, but how can we deliver the changed process?
There are serveral options to put the changed process in place:
Option 1: Parallel
The changed process coexists with the initial one for a period of time. Existing process instances must continue with the inital process definition.
Example: Users of the process are gradually trained to use the changed process. Some departments can still use the initial process, some use the new one. The process is triggered by IT systems as well. Those systems should have a smooth upgrade path.
Action: Create a new version of the process and deploy it in parallel to the one already in place.
|--- Startable V1 -------->
|--- Instances V1 -------->
|--- Startable V2 --------->
|--- Instances V2 -------->
Option 2: Merge
The changed process replaces the initial one. Existing process instances must continue using the changed process definition.
Example: Law changes render invalid the initial process. As of now all processes, including already running instances, must run with the latest process definition.
Action: Create a new version of the process and migrate existing instances to the new process definition.
|--- Startable V1 ------|--- Startable V2 ---------> |--- Instances V1 ------|--- Instances V1 + V2 ---->
Option 3: Phase Out
The changed process replaces the initial one. Existing process instances must continue with the inital process definition.
Example: Process analysis caused the process to be optimized, so that it can be executed in less time. All users should immediately use the changed process.
To keep effort low, already running process instances should continue running with the inital process definition.
Action: Create a new version of the process and deploy it in addition to the one already in place. Prevent the initial process version to be started by disabling the start events.
|--- Startable V1 --------|
|--- Instances V1 --------------------|
|--- Startable V2 --------->
|--- Instances V2 -------->
Be aware of endpoints:
If process versions are provided in parallel like in scenario 1 and 3 and connected to technical endpoints, for instance filedrops or web services, those endpoints might collide. Changing the structure of an endpoint, for instance the message payload, might cause incompatibility as well. In those cases (which are likely to happen) the endpoints must be versioned. Alternatively a dispatching mechanism can be used to route messages to the appropriate process version.
As you can see versioning is am important concept for process evolution. Which strategy to use depends on the process and the particular business requirements. The options introduced in this blog post might help to take the right decision. Make sure your process platform supports the options you need.
Are you interested to know how to combine process management, agility and Open Source software? Then the roadshow Agile Process Management with Open Source is for you. It is going to take place in several German cities during autumn 2012. I am going to present ways to achive efficiency in the area of process automation using proven Open Source technologies paired with agile approaches. In times where CIOs have to think twice before they spend IT budget, undoubtely an interesting topic to talk about. It have some interesting ideas to share and hope for inspiring discussions.
I have been using the Enterprise Architect modeling tool for many projects. I like the tool especially due to its quick modeling capabilities and productivity. Therefore is ideal for workshops with participants from IT and business. Performing live modeling together with the domain experts is a very efficient approach to gather accurate information related to processes and IT systems.
So I am very pleased to see that Enterprise Architect 9 now supports the creation of BPMN 2.0 models as well. And even better, models can be easily exported in form of BPMN 2.0 interchange format via Project – Model Publisher in the Enterprise Architect menubar (by the way, import is not possible. :-().
Anyway, I gave it a try and exported a simple model from EA:

To prove that the interchange works, I imported the model in my favorite BPMN tool the Signavio Modeler. This is the result:

That’s not too bad, is it? But it seems that some model details are missing. The dataInputAssociation and dataOutputAssociation, the scriptFormat and the groovy script attached to the ScriptTask were not imported.
It seems that (at least for those two tools) BPMN2.0 model interchange is not yet sufficiently possible.
Update:
I imported the bpmn file into the Activiti Designer Eclipse Plugin version 5.7.1 as you can see below:

The Groovy script was successfully imported, but the dataInputAssociation and dataOutputAssociation was not recognized and therefore removed from the process definition. The original file is solely used for the import. After importing an *.activiti file is created and used as THE model. On saving the model, a fresh BPMN XML file is generated. That is, you loose control over the file at the XML level. I personally don’t like this, as I think executable BPMN files should be treated as source code and need to be fully controlled by developers. A designer tool can help, as long as it does not destroy the orginal source files.
Summary so far:
Sparx Enterprise Architect – Comprehensive modeling, good export, no import
Signavio Modeler – Comprehensive modeling, good export, incomplete import
Activiti Designer – Limited modeling, good export, incomplete import
None of the tools has sound reverse engineering or roundtrip capabilities yet.
For descriptive (level 1) and analytical (level 2) modeling Sparx Enterprise Architect and Signavio Modeler are great.
For executable modeling (level 3) a plain XML editor seems to be the only reasonable option for the time being.