Almost every company today utilizes a kind of data warehouse or business intelligence solution for data analysis and reporting. Those solutions are primarily based on relational data, ETL jobs and reporting. Although powerful they are limited when it comes to very large data sets or realtime processing.
Some years ago the paradigm of Data Lakes was born to process very large data sets. Data Lakes are based on the idea of raw data processing, streaming data, ELT and machine learning.
What about combining the strengths of both into something even more powerful? This is what is called the Data Lakehouse, a term conceived by Databricks.
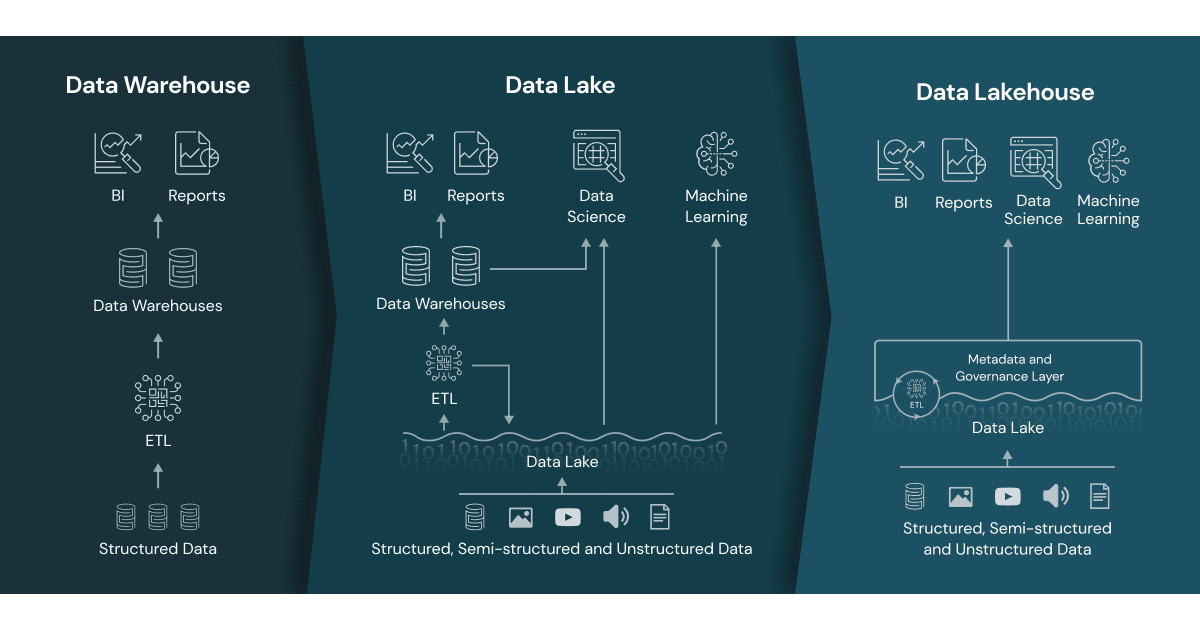
As the name suggests, it combines the strengths of Data Warehouses with the power of Data Lakes. Although the term Data Lakehouse was not really used in 2020, we built a Data Lakehouse for a logistics company already then.
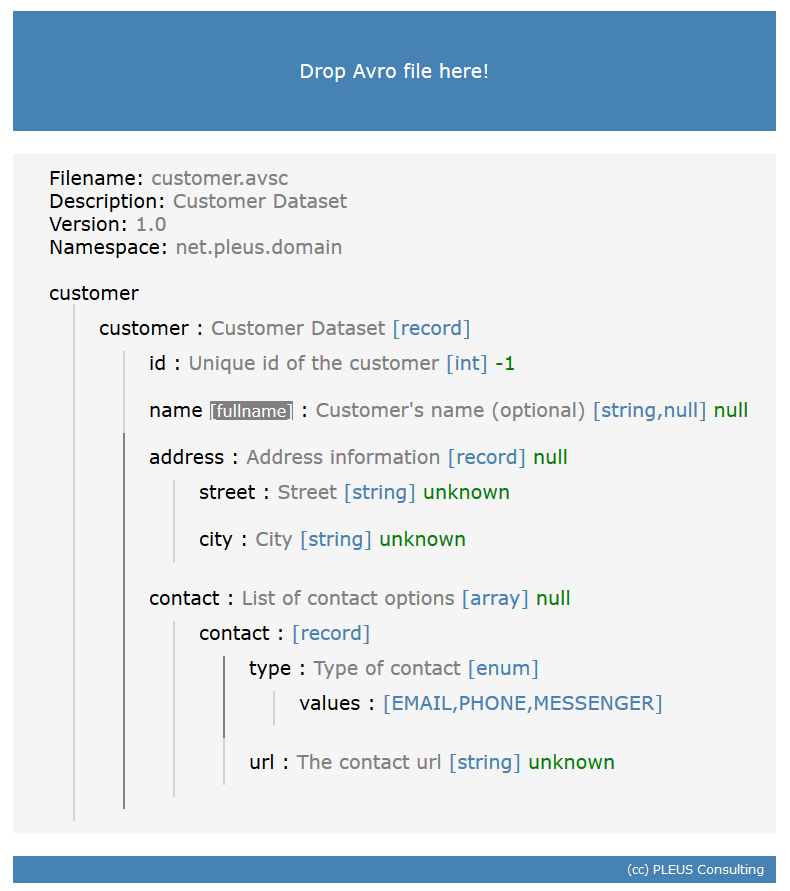
One of the main datasets in this project comprised 16 years or freight offers plus live data. The historical data was transferred from Oracle Databases to a new Data Lake. In addition stream sources were set up to ingest live data directly from the source applications into the Data Lake. The result was a huge active archive including historical and live data based on Hadoop, Spark, Kafka and HBase. The raw data was stored and continuously transformed into a normalized form ready to be processed by reporting and machine learning jobs. A logical structure, metadata and governance were added using Apache Atlas and Avro schemas. Reporting and end user security was implemented using Microsoft Power BI.
The result was something we would probably call a Data Lakehouse today. The combination of BI and Data Lake was very successful, so we created a success story to describe it.
To me is seems that Data Lakehouse is a very useful concept. It is an evolutionary step towards an integrated solution for processing and analysis of massive amounts of data by applying good practices in terms of governance, security and reporting. Surely something BI-Teams should have an eye on.