Since BPMN2.0 it is not only possible to design processes but to also execute them using a process engine. The process flow has a appropriate visual representation in the standard. But executable processes are mostly data driven. They interact with external services and exchange data with them. In addition to that processes maintain their own internal state. So a common requirement is to model the process internal state and connect to external services using the service data representation. BPMN is capable to include data definitions based on WSDL and XML Schemas, although the capabilities of the tools (that I know) to visualize data are somewhat limited.
In this blogpost I would like to show you how data looks like in BPMN and how a process can be linked in a standardized way to existing services based on WSDL and XSD.
The process is as simple as possible. The service is based on a BiPRO service description. The BiPRO is a standardization organisation in the German insurance market that standardizes processes and services at a technical and business level.
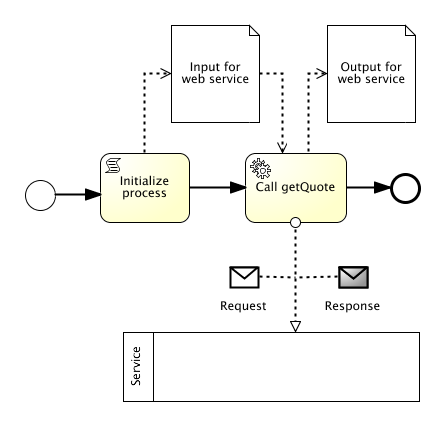
Below you see a simplyfied version in plain BPMN (when you import the bpmn below you will only see the events and tasks).
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="definitions" xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:bpmn="http://schema.omg.org/spec/BPMN/2.0"
xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI"
xmlns:dc="http://www.omg.org/spec/DD/20100524/DC"
xmlns:di="http://www.omg.org/spec/DD/20100524/DI"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.pleus.net/example"
xmlns:tns="http://www.pleus.net/example"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:nachrichten="http://www.bipro.net/namespace/nachrichten"
xmlns:bipro="http://www.bipro.net/namespace"
xsi:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL http://bpmn.sourceforge.net/schemas/BPMN20.xsd">
<!-- WSDL Import -->
<import importType="http://schemas.xmlsoap.org/wsdl/"
location="KompsitService_2.4.3.1.1.wsdl"
namespace="http://www.bipro.net/namespace" />
<!-- Item definition. Link to the external WSDL/XSD structure. structureRef: QName of input element -->
<itemDefinition id="getQuoteRequestItem" structureRef="nachrichten:getQuote" />
<itemDefinition id="getQuoteResponseItem" structureRef="nachrichten:getQuoteResponse" />
<!-- Message definitions. Link to the item definition. Can be visualized by using DI -->
<message id="getQuoteRequestMessage" itemRef="tns:getQuoteRequestItem" />
<message id="getQuoteResponseMessage" itemRef="tns:getQuoteResponseItem" />
<!-- Interface definition. implementationRef = QName of WSDL Port Type -->
<interface name="Komposit Interface" implementationRef="bipro:KompositServicePortType">
<!-- Operation: implementationRef = QName of WSDL Operation -->
<operation id="getQuoteOperation" name="getQuote Operation" implementationRef="bipro:getQuote">
<!-- Links to the message definitions -->
<inMessageRef>tns:getQuoteRequestMessage</inMessageRef>
<outMessageRef>tns:getQuoteResponseMessage</outMessageRef>
</operation>
</interface>
<process id="servicecall">
<!-- Datasources and targets for the service call (process state). Can be visualized by using DI and dataObjectReferences -->
<dataObject id="dataInputOfProcess" name="Input for webservice" itemSubjectRef="xs:string"/>
<dataObject id="dataOutputOfProcess" name="Output for webservice" itemSubjectRef="xs:string"/>
<!-- Process start -->
<startEvent id="start" />
<sequenceFlow id="flow1" sourceRef="start" targetRef="initScript" />
<!-- Initialization of process data -->
<scriptTask id="initScript" scriptFormat="groovy" name="Initialize process">
<script>
def temp = "2.4.3.1.1"
execution.setVariable("dataInputOfProcess", temp)
</script>
</scriptTask>
<sequenceFlow id="flow2" sourceRef="initScript" targetRef="webService" />
<!-- Web Service call -->
<serviceTask id="webService" name="Call getQuote" implementation="##WebService" operationRef="tns:getQuoteOperation">
<!-- Defines the inputs and outputs and links to item definitions -->
<ioSpecification>
<dataInput itemSubjectRef="tns:getQuoteRequestItem" id="dataInputOfServiceTask" />
<dataOutput itemSubjectRef="tns:getQuoteResponseItem" id="dataOutputOfServiceTask" />
<inputSet>
<dataInputRefs>dataInputOfServiceTask</dataInputRefs>
</inputSet>
<outputSet>
<dataOutputRefs>dataOutputOfServiceTask</dataOutputRefs>
</outputSet>
</ioSpecification>
<!-- Defines the mapping between process data and service input -->
<dataInputAssociation>
<sourceRef>dataInputOfProcess</sourceRef>
<targetRef>dataInputOfServiceTask</targetRef>
<assignment>
<from>
bpmn:getDataObject('dataInputOfProcess')
</from>
<to>
bpmn:getDataInput('dataInputOfServiceTask')/BiPROVersion/
</to>
</assignment>
</dataInputAssociation>
<!-- Defines the mapping between process data and service output -->
<dataOutputAssociation>
<sourceRef>dataOutputOfServiceTask</sourceRef>
<targetRef>dataOutputOfProcess</targetRef>
<assignment>
<from>
bpmn:getDataOutput('dataOutputOfServiceTask')/BiPROVersion/
</from>
<to>
bpmn:getDataObject('dataOutputOfProcess')
</to>
</assignment>
</dataOutputAssociation>
</serviceTask>
<sequenceFlow id="flow3" sourceRef="webService" targetRef="end" />
<!-- Process end -->
<endEvent id="end" />
</process>
Now let’s look at the example step-by-step.
1. Import the service: Line 16-18 imports the WSDL file that includes the types and messages used by the external service that we want to call from the process.
2. Define the items: Line 21-22 defines items that act as links to the types defined in the imported WSDL and XSD files.
3. Define the messages: Line 25-26 defines messages to be used in the interface definition that we see in the next step. Messages can be visualized by modeling tools provided that DI Information is present in the model.
4. Define the interface: The interface is the equivalent to the WSDL port type in BPMN. It is defined in line 29-36. So far we have itemDefinitions that link to the XSD-messages and an interface that links to the WSDL-port type. The inMessageRef and outMessageRef elements use the messages defined in step 3 to indirectly reference the itemDefinitions.
5. Define the process variables: The process maintains state. This state is defined in the form of dataObjects in line 41-42. Please note that the links to the external service are defined outside the process (which begins in line 38). The dataObjects are defined inside the process as they represent the data that is maintained by the respective process instances. By the way, when importing the process in a modeling tool, dataObjects are not visualized. To visualize dataObjects as a paper sheet, dataObjectReferences can be used. In this simple example we just use a string as input and output which transports a version information send to the BiPRO service and back. In a more complex senario this could be a type from an imported XSD.
6. Initialize the process: A simple BPMN script task (line 50-55) is used to initialize the dataObject dataInputOfProcess. It just sets the version to 2.4.3.1.1.
7. Link the serviceTask: The most complex part is the serviceTask (line 60-102). The operationRef attribute (line 60) links to the operation which is part of the interface definition (line 31). This is the web service operation to be called when the serviceTask is executed. The serviceTask comprises the elements ioSpecification (line 63-72), dataInputAssociation(line 75-86) and dataOutputAssociation (line 89-100). ioSpecification can be seen as a logical port that describes the service input and output from the perspective of the service. The itemSubjectRef attribute on the dataInput and dataOutput elements (line 64-65) link to the itemDefinitions (line 21-22) and as such to the data structures in the WSDL files. The id together with the inputSet and outputSet (line 66-71) define the connection points the serviceTask offers for sending and receiving data. dataInputAssociation and dataOutputAssociation map the dataObjects (process data) to the connection points or in other words to the request and response structures of the service (service data).
When the serviceTask webService is called, the process data from the dataObject dataInputOfProcess is copied to the web service request message nachrichten:getQuote/BIPROVersion. Then the service is called. After the service call finished, the version is copied from the response message nachrichten:getQuoteResponse/BIPROVersion to the dataObject dataOutputOfProcess.
This blogpost has shown how to link WSDL/XSD based services to BPMN processes in a standardized way.
Even if automated process execution is not in focus, it can be important to unambiguously link services to processes to create an integrated view of the entire process including its data.


